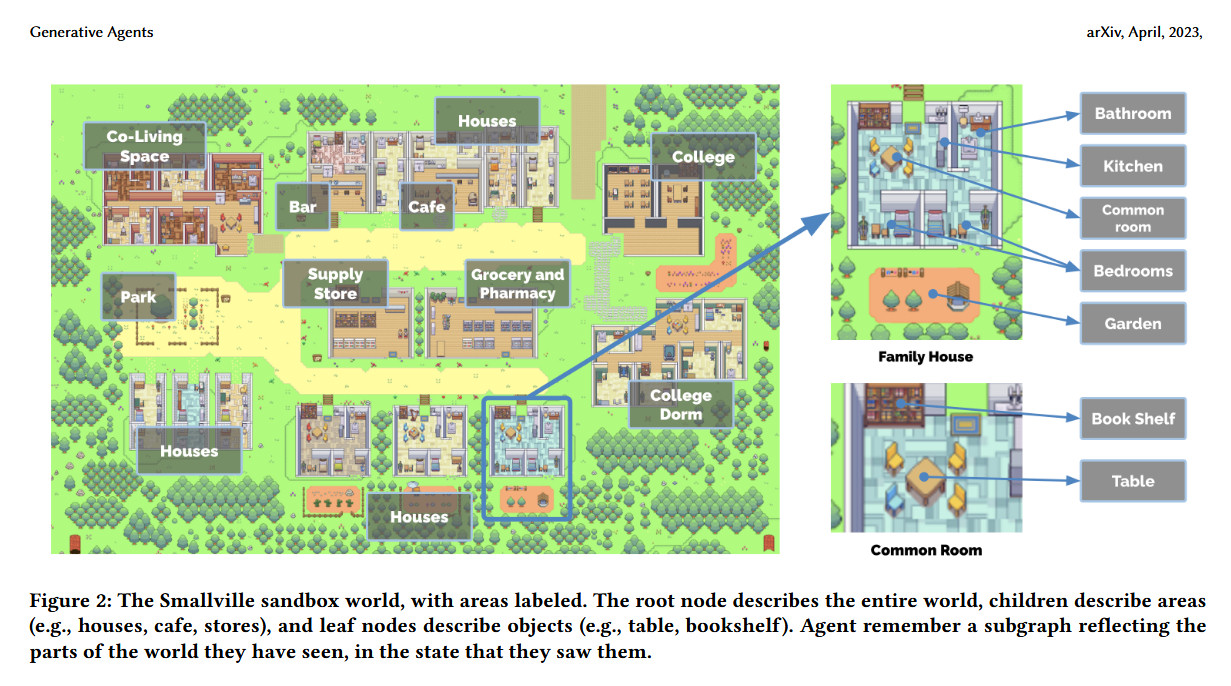
Ars Technica ci svela in questo articolo dedicato a "Smallville" una città RPG nella quale i ricercatori studiano i comportamenti emergenti dell'IA in un mondo sandbox ispirato a The Sims. E succedono cose sorprendenti quando si mettono insieme 25 agenti di intelligenza artificiale in un contesto del genere.
"Gli agenti generativi si svegliano, preparano la colazione e si recano al lavoro; gli artisti dipingono e gli autori scrivono; si formano opinioni, si accorgono l'uno dell'altro e avviano conversazioni; ricordano e riflettono sui giorni passati mentre pianificano il giorno successivo", scrivono i ricercatori nel loro articolo: "Generative Agents: Interactive Simulacra of Human Behavior".
Per studiare il gruppo di agenti AI, i ricercatori hanno creato una città virtuale chiamata "Smallville", che comprende case, un bar, un parco e un negozio di alimentari. Ai fini dell'interazione tra P"N"G, il mondo è rappresentato sullo schermo da una vista dall'alto, utilizzando una grafica pixel in stile retrò che ricorda un classico RPG giapponese a 16 bit.
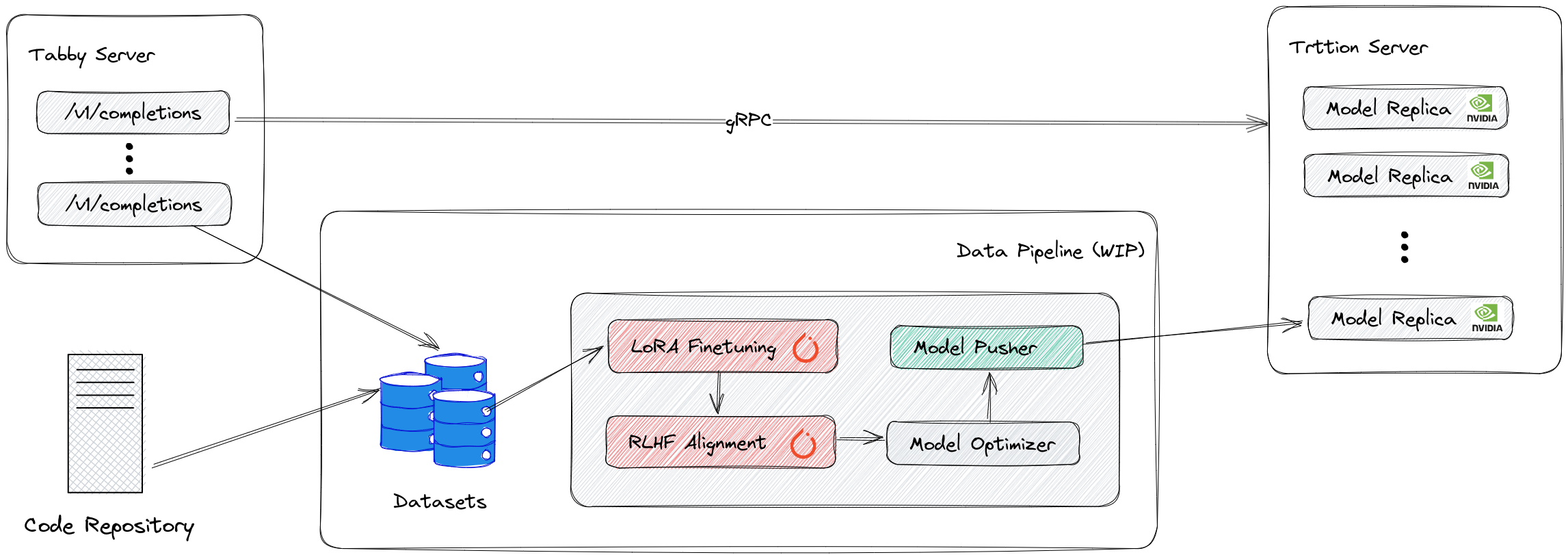
Tabby è un assistente AI alla programmazione in hosting locale. Un'alternativa opensource / on-premise di GitHub Copilot. E' ancora in fase alfa.
Caratteristiche:
- Autosufficiente, non necessita di un DBMS o di un servizio cloud.
- Interfaccia web per la visualizzazione e la configurazione di modelli e MLOP.
- Interfaccia OpenAPI, facile da integrare con l'infrastruttura esistente (ad esempio Cloud IDE).
- Supporto delle GPU di livello consumer (FP-16 weight loading con varie ottimizzazioni).
- Richiede Pascal or newer NVIDIA GPU
Silicon Valley's Midlife Crisis Is Destroying The Internet (2.0) è la storia di come, dapprima, le aziende di social media hanno trasformato il selvaggio west dell'open web in un giardino recintato (walled garden) e, in un secondo momento, di come hanno deciso di trasformare quel giardino recintato in un country club in cui si deve pagare per vedere i propri contenuti fino ad ora gratuiti.
Questa volta parliamo come in elettronica tutto sia un rapidissimo orologio fatto di mapper e interrupt, e tutto parte dall'oscillatore al quarzo che dà la velocità di clock. Per quanto riguarda l'uscita video ? Meglio tenersi stretti gli impulsi di sincronizzazione.
Quando ChatGPT scrive qualcosa come un saggio, ciò che fa è chiedersi ripetutamente "dato il testo fino a qui, quale dovrebbe essere la prossima parola ?",
Questa "parola" aggiunta si definisce "token", e potrebbe anche essere incompleto, per cui a volte possono essere "inventate nuove parole". Ad ogni passo si ottiene un elenco di parole con le relative probabilità.
Se a volte (a caso) si scelgono parole di rango inferiore, si può ottenere un saggio "più interessante".
Il parametro che regola questa scelta si chiama "temperatura", e determina la frequenza con cui vengono usate le parole di rango più basso; in molti casi una "temperatura" di 0,8 sembra essere l'ideale.
Con l'addestramento su un numero sufficiente di testi in lingua, si possono ottenere stime abbastanza buone non solo per le probabilità di singole lettere o coppie di lettere (2-grammi), ma anche per serie di lettere più lunghe. Ad esempio ci sono circa 40.000 parole ragionevolmente usate in inglese.
Esaminando un ampio corpus di testi in inglese (ad esempio qualche milione di libri, con un totale di qualche centinaio di miliardi di parole), possiamo ottenere una stima di quanto sia comune ogni parola.
E con questa si può iniziare a generare "intere frasi", in cui ogni parola è scelta indipendentemente a caso, con la stessa probabilità che appaia nel corpus.
Come per le lettere, possiamo iniziare a prendere in considerazione non solo le probabilità per le singole parole, ma anche quelle per le coppie o per gli n-grammi di parole più lunghi.
Supponiamo di voler sapere (come fece Galileo alla fine del 1500) quanto tempo impiegherà una palla di cannone lanciata da ogni piano della Torre di Pisa a toccare il suolo. Si potrebbe misurare in ogni caso e fare una tabella dei risultati. Immaginiamo di avere dei dati (un po' idealizzati) su quanto tempo impiega una palla di cannone a cadere da vari piani: come facciamo a capire quanto tempo impiega a cadere da un piano di cui non abbiamo dati espliciti?
In questo caso particolare, possiamo usare le leggi fisiche conosciute per calcolarlo.
E da questa linea retta possiamo stimare il tempo di caduta per qualsiasi piano.
Ma per ChatGPT dobbiamo creare un modello di testo in lingua umana del tipo prodotto da un cervello umano. E per una cosa del genere non abbiamo (almeno per ora) nulla di simile alla "matematica semplice".
Se il nostro obiettivo è produrre un modello di ciò che gli esseri umani possono fare nel riconoscimento delle immagini, la vera domanda da porsi è cosa avrebbe fatto un essere umano se gli fosse stata presentata una di quelle immagini sfocate, senza sapere da dove provenisse.
Abbiamo un "buon modello" se i risultati che otteniamo dalla nostra funzione concordano tipicamente con quello che direbbe un umano.
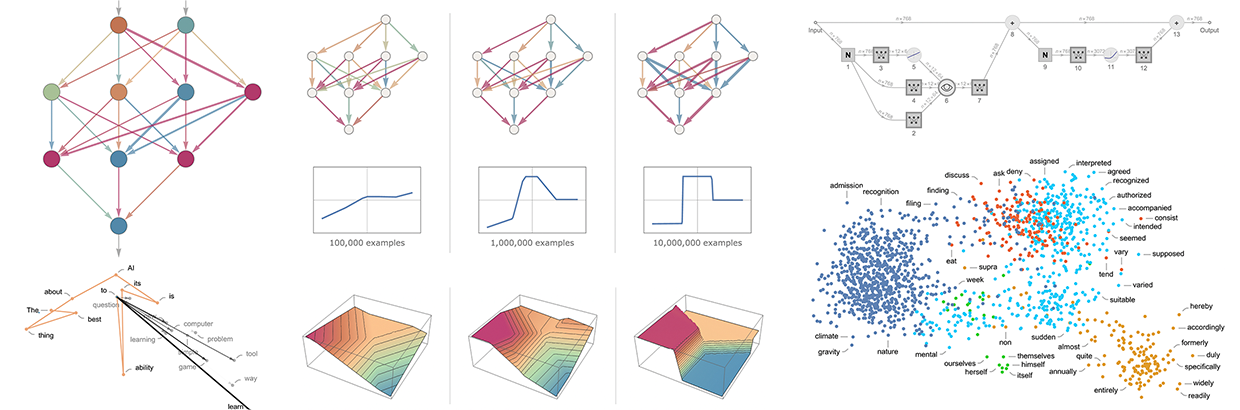
L'approccio attuale più popolare, e di successo, utilizza le reti neurali. Inventate negli anni '40, in una forma molto simile a quella attuale, le reti neurali possono essere considerate come semplici idealizzazioni del funzionamento del cervello.
La configurazione di un "diagramma di Voronoi" separa i punti nello spazio euclideo 2D; il compito di riconoscimento delle cifre può essere pensato come se facesse qualcosa di molto simile, ma in uno spazio a 784 dimensioni formato dai livelli di grigio di tutti i pixel di ogni immagine.
Soprattutto nell'ultimo decennio, ci sono stati molti progressi nell'arte dell'addestramento delle reti neurali.
Ma per lo più le cose sono state scoperte per tentativi ed errori, aggiungendo idee e trucchi che hanno progressivamente costruito una tradizione significativa su come lavorare con le reti neurali.
Questo non vuol dire che non esistano "idee strutturanti" rilevanti per le reti neurali.
Così, ad esempio, avere matrici di neuroni in 2D con connessioni locali sembra almeno molto utile nelle prime fasi di elaborazione delle immagini.
E le attuali reti neurali, con gli attuali approcci all'addestramento delle reti neurali, si occupano specificamente di matrici di numeri.
Ora c'è il problema di ottenere i dati con cui addestrare la rete.
Molte delle sfide pratiche legate alle reti neurali e all'apprendimento automatico in generale si concentrano sull'acquisizione o sulla preparazione dei dati di addestramento necessari. Quanti dati bisogna mostrare a una rete neurale per addestrarla a un compito particolare?
In generale, le reti neurali hanno bisogno di "vedere molti esempi" per allenarsi bene.
È inoltre necessario mostrare alla rete neurale variazioni dell'esempio.
Perché usare "sd" rispetto agli strumenti esistenti come "sed" ?
Il comando "sd" utilizza la sintassi delle espressioni regolari già nota da JavaScript, Python e Perl. Però senza avere a che fare con le stranezze di "sed" e "awk" e per diventare subito produttivi.
La "Modalità stringa-letterale" trova e sostituisce senza ricorrere alle regex. Non è più necessario ricordare quali caratteri sono speciali e devono essere evasi. E' facile da leggere, facile da scrivere.
Le espressioni di ricerca e sostituzione sono suddivise, il che le rende facili da leggere e scrivere. Non è più necessario fare i conti con gli slash non chiusi e quelli sfuggiti.
Le impostazioni predefinite sono scelte in modo intelligente e con buon senso, adattate all'uso quotidiano.
Videocard Virtual Museum è un museo virtuale delle schede video ed è anche una notevole collezione personale. Il proprietario ha iniziato a collezionare schede nell'aprile 2011. Ci si possono trovare anche le specifiche tecniche, le foto, i driver e informazioni particolari.