Open Syllabus Project è un'organizzazione di ricerca no-profit che raccoglie e analizza milioni di syllabi per supportare nuove applicazioni di insegnamento e apprendimento. Open Syllabus aiuta gli insegnanti a sviluppare corsi, le biblioteche a gestire collezioni e le case editrici a sviluppare libri. Sostiene gli studenti e i docenti nella loro esplorazione di argomenti e campi per migliorare i materiali didattici, utilizzando licenze aperte. Sostiene il lavoro di allineamento dell'istruzione superiore alle esigenze del mercato del lavoro e di facilitazione della mobilità degli studenti. Inoltre, sfida le facoltà e le università a lavorare insieme per gestire questa importante risorsa di dati.
Open Syllabus dispone attualmente di un corpus di nove milioni di syllabi in lingua inglese provenienti da 140 Paesi. Utilizza l'apprendimento automatico e altre tecniche per estrarre citazioni, date, campi e altri metadati da questi documenti. I dati che ne derivano sono resi liberamente disponibili attraverso Syllabus Explorer (Galaxy).
History Defined (twitter), tra le mille e mille altre cose, ci svela la storia e le origini di uno dei simboli americani dell'occultismo: la Tavoletta Ouija.
Gli scienziati ne sono incuriositi e gli esperimenti scientifici indicano che la planchette della Ouija si muove "da sola" grazie all'"effetto ideomotorio", un meccanismo scoperto decenni prima della teoria della mente inconscia di Sigmund Freud. L'effetto ideomotorio è un fenomeno psicologico per cui il cervello controlla inconsciamente i movimenti muscolari del corpo in risposta a stimoli esterni. Questo ha portato i ricercatori a considerare la mente inconscia in una serie di esperimenti che supportano l'idea che la mente inconscia sia molto più intelligente di quanto si sapesse. Ciò significa che è in grado di ricavare informazioni che non sono accessibili alla mente cosciente.
Steven Belledin è cresciuto in Pennsylvania e ha iniziato la sua carriera completando i compiti artistici del liceo per le sue sorelle maggiori. Dopo il liceo è fuggito dalla vita della piccola città per nascondersi a New York e diventare un pittore. Quattro anni dopo, è uscito dai cancelli del Pratt Institute e si è subito tuffato a testa bassa nel muro di mattoni dell'illustrazione.
Tra i suoi clienti figurano Harper Collins, Estee Lauder Companies, Wizards of the Coast, Upperdeck, Fantasy Flight Games, Hidden City Games e altri.
I suoi lavori sono stati esposti in Fantasy+ 3, Spectrum, la Society of Illustrators 49th Annual Exhibition, la Society of Illustrators 49th Annual Traveling Exhibition e in altre pubblicazioni e mostre.
Nell'estate del 2021, Mac Premo decise che aveva trascorso abbastanza tempo creare arte con un significato prestabilito. Voleva vedere com'era creare libero da quell'obbligo. Voleva vedere cosa sarebbe successo se avesse lasciato che il processo gli parlasse. Così ha raccolto il suo vasto arsenale di materiali con cui realizza collage e sculture e ha creato una pila di carta alta circa 30 centimetri. Con questa materia prima, ha messo da parte l'idea di un'espressione esteriore con un programma specifico e ha abbracciato l'esplorazione interiore armato solo di curiosità.
In seguito, ogni collage è diventato un racconto indipendente. Parlava in un linguaggio intuitivo su cui forse non aveva il controllo totale. Era un po' inquietante ma anche liberatorio.
Sapeva che anche se non avesse compreso appieno ciò che stava creando, ci sarebbero state due persone ci sarebbero riuscite: i suoi figli. Per essere chiari, non si intende "capire" nel modo in cui si elabora un linguaggio chiaro, si intende che questi pezzi potrebbero avere una risonanza poetica con le due persone che lo conoscono meglio di quanto lui conosca sé stesso.
genuary.art succede durante il mese di gennaio 2023 e tutti sono invitati a partecipare.
Ogni 24 ore ci sarà un nuovo prompt per sbizzarrirsi con il proprio codice artistico.
Non è necessario seguire esattamente il prompt e si può usare qualsiasi linguaggio, framework o mezzo.
Tra le opere più significative:
Virginia Woolf, "Verso il faro"
Arthur Conan Doyle, "Il libro dei casi di Sherlock Holmes"
A. A. Milne, "Ora siamo in sei", illustrazioni di E. H. Shepard
Ernest Hemingway, "Uomini senza donne" (raccolta di racconti)
William Faulkner, "Le zanzare"
Agatha Christie, "I quattro grandi"
Edith Wharton, "Il sonno del crepuscolo"
Herbert Asbury, "Le bande di New York" (pubblicazione originale del 1927)
Franklin W. Dixon (pseudonimo), "Il tesoro della torre" (il primo libro degli Hardy Boys)
Hermann Hesse, "Der Steppenwolf" (nell'originale tedesco)
Franz Kafka, "Amerika" (nell'originale tedesco)
Marcel Proust, "Le Temps retrouvé"
Quando ChatGPT scrive qualcosa come un saggio, ciò che fa è chiedersi ripetutamente "dato il testo fino a qui, quale dovrebbe essere la prossima parola ?",
Questa "parola" aggiunta si definisce "token", e potrebbe anche essere incompleto, per cui a volte possono essere "inventate nuove parole". Ad ogni passo si ottiene un elenco di parole con le relative probabilità.
Se a volte (a caso) si scelgono parole di rango inferiore, si può ottenere un saggio "più interessante".
Il parametro che regola questa scelta si chiama "temperatura", e determina la frequenza con cui vengono usate le parole di rango più basso; in molti casi una "temperatura" di 0,8 sembra essere l'ideale.
Con l'addestramento su un numero sufficiente di testi in lingua, si possono ottenere stime abbastanza buone non solo per le probabilità di singole lettere o coppie di lettere (2-grammi), ma anche per serie di lettere più lunghe. Ad esempio ci sono circa 40.000 parole ragionevolmente usate in inglese.
Esaminando un ampio corpus di testi in inglese (ad esempio qualche milione di libri, con un totale di qualche centinaio di miliardi di parole), possiamo ottenere una stima di quanto sia comune ogni parola.
E con questa si può iniziare a generare "intere frasi", in cui ogni parola è scelta indipendentemente a caso, con la stessa probabilità che appaia nel corpus.
Come per le lettere, possiamo iniziare a prendere in considerazione non solo le probabilità per le singole parole, ma anche quelle per le coppie o per gli n-grammi di parole più lunghi.
Supponiamo di voler sapere (come fece Galileo alla fine del 1500) quanto tempo impiegherà una palla di cannone lanciata da ogni piano della Torre di Pisa a toccare il suolo. Si potrebbe misurare in ogni caso e fare una tabella dei risultati. Immaginiamo di avere dei dati (un po' idealizzati) su quanto tempo impiega una palla di cannone a cadere da vari piani: come facciamo a capire quanto tempo impiega a cadere da un piano di cui non abbiamo dati espliciti?
In questo caso particolare, possiamo usare le leggi fisiche conosciute per calcolarlo.
E da questa linea retta possiamo stimare il tempo di caduta per qualsiasi piano.
Ma per ChatGPT dobbiamo creare un modello di testo in lingua umana del tipo prodotto da un cervello umano. E per una cosa del genere non abbiamo (almeno per ora) nulla di simile alla "matematica semplice".
Se il nostro obiettivo è produrre un modello di ciò che gli esseri umani possono fare nel riconoscimento delle immagini, la vera domanda da porsi è cosa avrebbe fatto un essere umano se gli fosse stata presentata una di quelle immagini sfocate, senza sapere da dove provenisse.
Abbiamo un "buon modello" se i risultati che otteniamo dalla nostra funzione concordano tipicamente con quello che direbbe un umano.
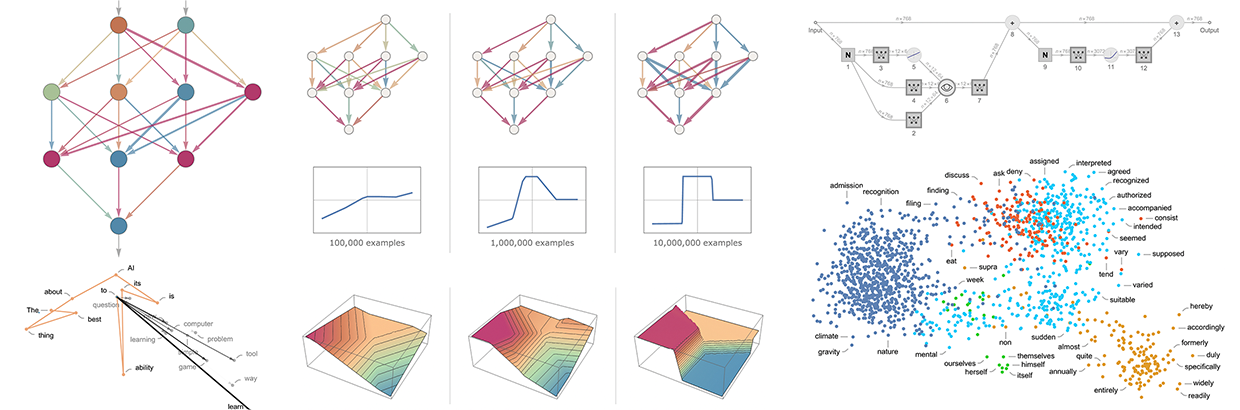
L'approccio attuale più popolare, e di successo, utilizza le reti neurali. Inventate negli anni '40, in una forma molto simile a quella attuale, le reti neurali possono essere considerate come semplici idealizzazioni del funzionamento del cervello.
La configurazione di un "diagramma di Voronoi" separa i punti nello spazio euclideo 2D; il compito di riconoscimento delle cifre può essere pensato come se facesse qualcosa di molto simile, ma in uno spazio a 784 dimensioni formato dai livelli di grigio di tutti i pixel di ogni immagine.
Soprattutto nell'ultimo decennio, ci sono stati molti progressi nell'arte dell'addestramento delle reti neurali.
Ma per lo più le cose sono state scoperte per tentativi ed errori, aggiungendo idee e trucchi che hanno progressivamente costruito una tradizione significativa su come lavorare con le reti neurali.
Questo non vuol dire che non esistano "idee strutturanti" rilevanti per le reti neurali.
Così, ad esempio, avere matrici di neuroni in 2D con connessioni locali sembra almeno molto utile nelle prime fasi di elaborazione delle immagini.
E le attuali reti neurali, con gli attuali approcci all'addestramento delle reti neurali, si occupano specificamente di matrici di numeri.
Ora c'è il problema di ottenere i dati con cui addestrare la rete.
Molte delle sfide pratiche legate alle reti neurali e all'apprendimento automatico in generale si concentrano sull'acquisizione o sulla preparazione dei dati di addestramento necessari. Quanti dati bisogna mostrare a una rete neurale per addestrarla a un compito particolare?
In generale, le reti neurali hanno bisogno di "vedere molti esempi" per allenarsi bene.
È inoltre necessario mostrare alla rete neurale variazioni dell'esempio.